Fast neun Monate nach dem Release von LLama 2 hat Meta endlich den Nachfolger des beliebten Open Source KI-Modells vorgestellt. In ersten Benchmarks wird deutlich, welches Potenzial in der neuen Version des Large Language Models des Facebook-Konzerns schlummert.
Die ersten beiden Modelle der neuen Llama Generation tragen die Namen Llama 3 8B und Llama 3 70B. Das B im Modellnamen steht für die jeweilige Größe des Modells und entsprechend der Anzahl der für das Training verwendeten Parameter.
Die Anzahl der Parameter ist überraschenderweise nicht wirklich höher als bei LLaMa-2, welches in drei Versionen mit jeweils 7,13 und ebenfalls 70 Milliarden Parametern veröffentlicht wurde.

Das beste Open-Source KI-Modell?
Laut Meta soll das neue Modell trotz derselben Größe deutlich leistungsstärker sein und vor allem über bessere Fähigkeiten in Bezug auf Logik verfügen.
Meta betont außerdem, dass die beiden Modelle nur die ersten in der neuen Generation sein werden und sie insbesondere das Feedback der Open-Source-Community schätzen. Das ist auch der Grund, die neuen Modelle so schnell wie möglich der breiten Masse zur Verfügung zu stellen und so die Verbesserung und Optimierung der neuen Modell-Familie voranzutreiben.
Das ausgerufene Ziel von Meta ist, die gesamte Llama 3 Generation in der nahen Zukunft mit multimodalen und mehrsprachigen Fähigkeiten auszustatten und so die gesamte Welt mit einem enorm fähigen Open-Source-Modell zu versorgen.
Des Weiteren soll die Kontextlänge um ein Vielfaches erhöht werden, um komplexere Anwendungen zu ermöglichen und auch die Programmierfähigkeiten des Modells zu verbessern.
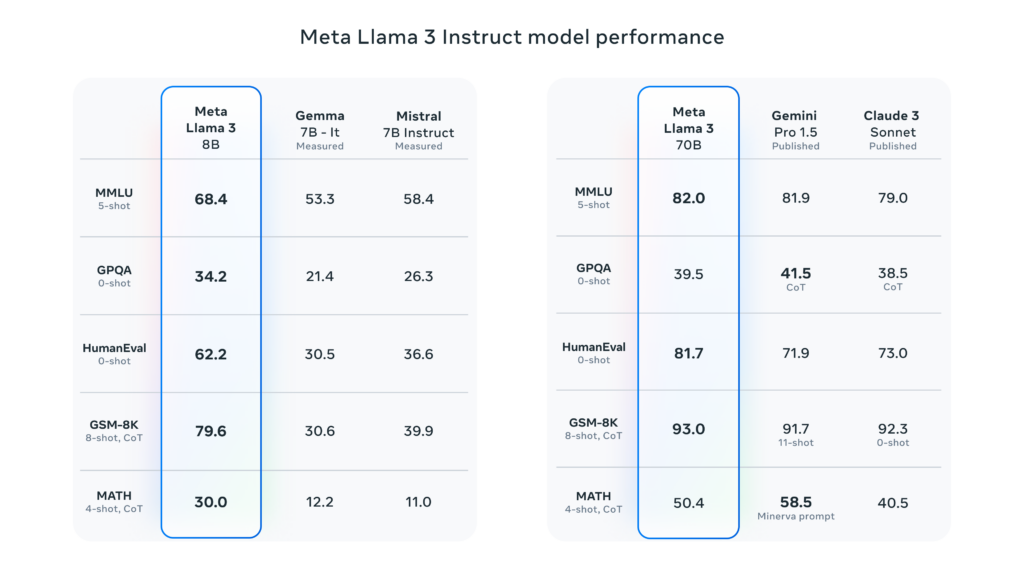
Im direkten Vergleich mit anderen Modellen mit einer ähnlichen Anzahl an Parametern scheint Meta tatsächlich in einigen Kategorien die Nase vorn zu haben. Allerdings haben wir mittlerweile gelernt, solchen Benchmarks nicht allzu viel Bedeutung zuzumessen.
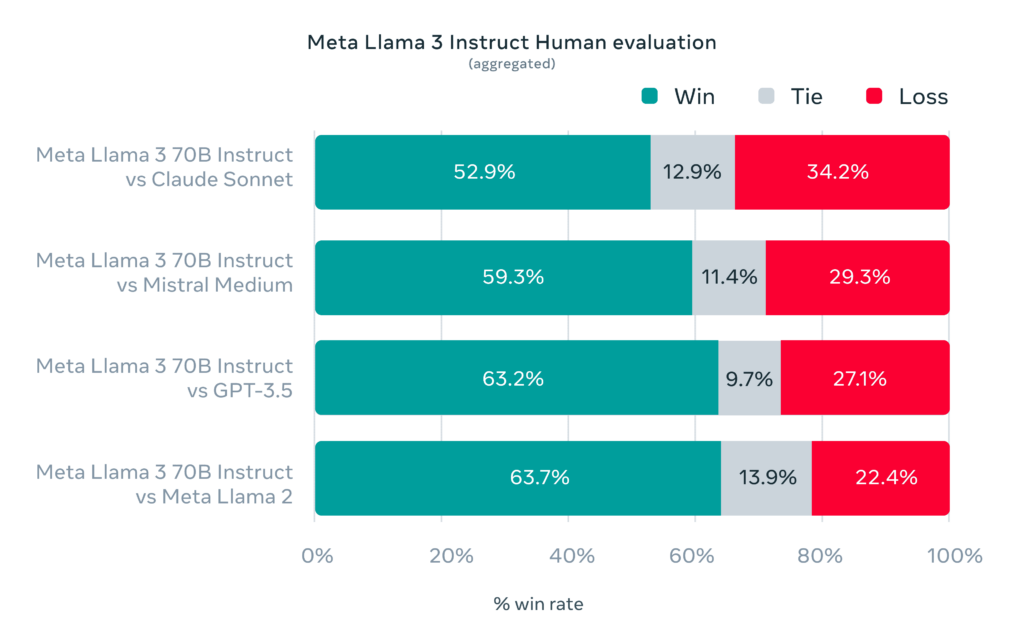
Viel interessanter ist der nächste Test, den Meta in ihrem Blogpost zu Llama 3 veröffentlicht haben. Hier wurde nämlich tatsächlich mit Menschen gearbeitet und das neue Modell anhand von 1800 Prompts und 12 unterschiedlichen Szenarien auf Herz und Nieren geprüft. Dabei ging es von simplen Fragen nach Rat und kreativen Aufgaben bis hin zur Softwareprogrammierung und der Arbeit mit Text.
Insbesondere bei der Arbeit mit Sprache und mehrstufigen Aufgaben soll das neue Modell die verbesserten Fähigkeiten zeigen können. Außerdem soll Llama 3 in der Lage sein, den Kontext eines Gesprächs besser zu verstehen und weniger dazu neigen, Antworten auf bestimmte Fragen zu verweigern.
Spannend ist, dass Meta angibt, den eigenen Mitarbeitenden keinen Zugriff auf diese Trainingsszenarien zu geben, um zu vermeiden, dass die Llama 3 Modelle zu sehr auf diese speziellen Anwendungsfälle geschult werden.
Im Vergleich mit Claude Sonnet, Mistral Medium und GPT-3.5 konnte sich Llama 3 tatsächlich gegen alle Konkurrenten souverän durchsetzen und auch das Vorgängermodell Llama 2 musste sich dem neuen Modell Llama 3 70B Instruct geschlagen geben.
Im klassischen Vergleich der Large Language Modelle anhand der üblichen Tests konnten sich sowohl die 8B als auch die 70B Version gegen vergleichbare Modelle nicht nur behaupten, sondern sie sogar übertreffen.
Der Vollständigkeit halber sei allerdings gesagt, dass Llama 3 8B gegen Mistral 7B und Gemma 7B von Google angetreten ist und diese beiden Modelle über eine Milliarde Parameter weniger verfügen.
Ein weiterer Nachteil, mit dem wir uns außerhalb des englischen Sprachraums herumärgern müssen, ist, dass Meta direkt angibt, dass Llama 3 auf Englisch am besten funktioniert. Wenigstens sind knappe 5 % der Trainingsdaten des neuen Modells auf anderen Sprachen als Englisch. Um welche Sprachen es sich dabei genau handelt, sagt Meta im Blogpost allerdings nicht.
Mit welchen Daten wurde Llama 3 trainiert?
Llama 3 wurde mit mehr als 15 Billionen Token trainiert und hatte damit laut Meta mehr als das siebenfache an Trainingsdaten als Llama 2 und mehr als das vierfache an Code, welcher für das Training verwendet wurde. Zusätzlich wurden mehr als 10 Millionen von Menschen überwachte Beispiele für das Training verwendet.
Besonders interessant ist natürlich auch die, im Vergleich zum Vorgängermodell, verdoppelte Kontextlänge von 8000 Tokens, mit der sehr viel komplexere Arbeiten möglich werden.
Als Quelle für die Trainingsdaten gibt Meta an, sich an öffentlich zugänglichen Daten bedient zu haben und betont ausdrücklich keinerlei Daten von Meta-Usern verwendet zu haben.
Stattdessen hat sich Meta das Vorgängermodell zunutze gemacht und dafür verwendet, qualitativ hochwertige Trainingsdaten zu identifizieren. Diese wurden dann verwendet, um Llama 3 zu trainieren und weitere Datensätze für die neue Generation zu erstellen.
Llama 3 400B: das größte Open Source Large Language Modell
Einen kurzen Ausblick in die Zukunft hat Meta auch schon gegeben. Das Unternehmen arbeitet aktuell an einem Llama 3 Modell mit 400 Milliarden Parametern, welches sich aktuell noch in der Entwicklung und Trainingsphase befindet.
Das 400B+ Modell soll neben der angestrebten Multimodalität auch über eine extrem gute Sprachverarbeitung in unterschiedlichsten Sprachen verfügen und ein deutlich vergrößertes Kontext-Fenster beinhalten.
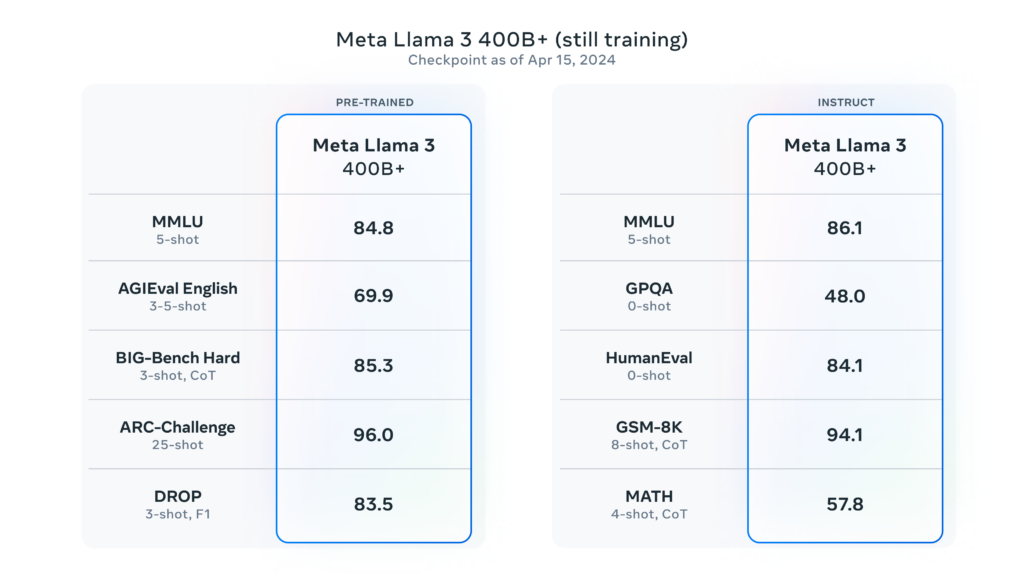
Dr. Jim Fan, einer der führenden Köpfe für AI bei Nvidia hat die veröffentlichten Zahlen mal mit den bekannten Ergebnissen von den momentan stärksten Modellen wie Claude 3 Opus und GPT 4 Turbo verglichen. Und da muss man ganz klar sagen, dass selbst das 400B Modell diese beiden Modelle noch nicht schlagen kann. Allerdings muss man das Ganze hier auch in Relation setzen. Wir sprechen über ein Open Source Modell, welches nahezu identische Ergebnisse in diesen Tests erzielt wie die proprietären Marktführer.
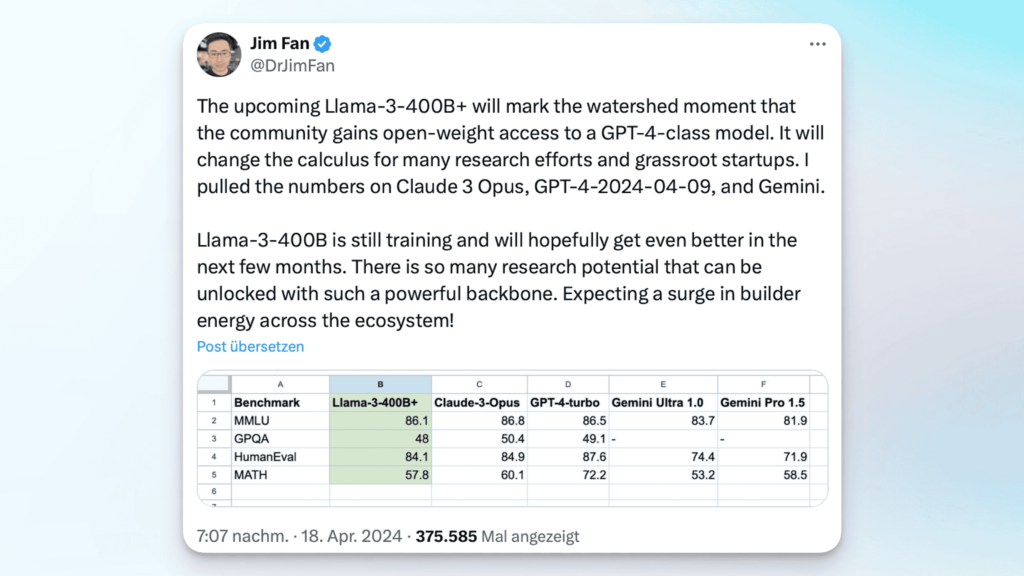
Hier den Anspruch zu haben, diese Modelle direkt zu übertreffen, ist fehl am Platz. Stattdessen können wir uns darüber freuen, dass mithilfe der gesamten Open Source Gemeinschaft hier ein unfassbar leistungsstarkes Modell, hoffentlich bald, verfügbar gemacht wird. Und nur so als kleine Zusatzinformation: die beiden Gemini Modelle Gemini Pro und Gemini Ultra konnte das 400er-Modell bereits jetzt schon in allen Disziplinen außer Mathematik übertreffen.
Beide aktuell veröffentlichten Llama 3 Varianten sind übrigens schon jetzt in der Chatbot-Arena verfügbar und können dort ohne Login und kostenlos getestet werden. Das Beste daran: Wir können hier ja sogar beide Modelle direkt vergleichen oder auch gegen andere existierende Open Source aber auch Closed Source Modelle testen und so zum Beispiel herausfinden, wie sich Llama 3 gegen unseren aktuellen Open Source Favoriten Command R Plus schlagen kann.
Meta behauptet natürlich, dass das Llama jetzt das beste Open-Source-Modell auf dem Markt ist, diese These wird jetzt direkt auf die Probe gestellt.
Denn wir sind sehr gespannt, wie das Leaderboard aussehen wird, sobald in der Arena genügend Daten gesammelt wurden. Das dürfte sehr bald der Fall sein und hilft bei einer realistischeren Einschätzung der Performance des neuen Modells, da hier ja wirklich von normalen Usern bewertet wird, wie gut oder schlecht die Modelle die Anfragen beantworten.
Neben den neuen Llama Modellen hat Meta aber auch Meta.ai vorgestellt – was man sich so ein bisschen vorstellen kann wie das ChatGPT von Facebook. Wir bekommen einen Assistenten, der hauptsächlich einmal ein Chatbot ist, in dem wir die neuen Llama Modelle verwenden können. Genau so, wie wir eben die GPT-Modelle von OpenAI in deren Chatbot ChatGPT verwenden.
Neben diesem einfachen Chatbot soll Meta.ai auch in andere Dienste des Konzerns integriert werden, zum Beispiel die Messenger. Aktuell ist das ganze allerdings nur auf Englisch in ausgewählten Ländern verfügbar – Deutschland gehört nicht dazu. Wer Meta.ai also schon jetzt ausprobieren will, muss zum Beispiel auf VPN-Services zurückgreifen.
Wir sind gespannt, wann der KI-Assistent von Meta dann auch in Europa und vor allem Deutschland verfügbar ist und halten euch hier natürlich auf dem Laufenden. Sobald es da Neuigkeiten gibt, erfahrt ihr es bei uns als Erstes.
