Schon Ende 2023 hat die Mozilla Foundation ein neues Projekt mit dem Namen Llamafile zum ersten Mal vorgestellt, mit dem es möglich ist, fähige KI-Modelle in nur einer ausführbaren Datei zu verpacken und lokal und komplett anonym auf dem eigenen Computer zu nutzen.
Das ist allerdings für lange Zeit ziemlich unter dem Radar geflogen bis Llamafile am 26. Juni von Stephen Hood und Justine Tunney nochmal bei der AI Engineering World’s Fair vorgestellt wurde und die beiden gezeigt haben, welche Fortschritte Mozilla mittlerweile machen konnte.
Hier kann man sich die Aufzeichnung des Vortrags ansehen, der Part der beiden beginnt bei ca. Minute 53:

Die Implikationen dieses Open Source Projekts scheinen bis jetzt immer noch nicht wirklich final in der KI-Community angekommen zu sein, aber es ist unglaublich, welche Möglichkeiten Llamafile bietet, um allen die Nutzung von intelligenten KI-Modellen auf der eigenen Hardware, egal ob Mac, Windows PC oder sogar Raspberry und vielleicht bald Smartphones zu ermöglichen.
In diesem Artikel zeigen wir, wie man Llamafile benutzt, welche Stolpersteine es gibt und welche Tipps man aktuell für die beste Hardware geben kann, um auch die Top-Modelle nutzen zu können, die eben entsprechend mehr Leistung benötigen.
- Was ist Llamafile überhaupt?
- Wo finde ich Llamafile?
- Wie kann ich mit Llamafile KI-Modelle lokal verwenden?
- Was ist die beste Hardware für Llamafile?
- Mögliche Probleme bei der Arbeit mit dem Terminal
Was ist Llamafile überhaupt?
Fangen wir an mit der offiziellen Definition aus dem Blogpost zur Ankündigung von Llamafile:
„Llamafile erlaubt es uns die öffentlich verfügbaren Gewichte von großen Sprachmodellen in eine ausführbare Datei zu konvertieren.“
Das klingt jetzt erstmal ziemlich unspektakulär, bzw. versteht nicht jeder, was das eigentlich heißen soll. Die Gewichte, die bei den Open Source Modellen frei verfügbar sind, sind vereinfacht gesagt die Parameter oder Einstellungen des Modells, die dafür sorgen, dass es gute Antworten gibt. Aber erst einmal sind das einfach nur riesige Dateien, die man so nicht einfach „benutzen“ kann, um das Modell zu verwenden.
Hier kommt Llamafile ins Spiel und macht ganz einfach für uns aus diesen riesigen Dateien mit den Gewichten eine einzige ausführbare Datei, die wir auf dem eigenen Rechner starten können und dann einen einfachen Chatbot lokal und offline verwenden, der das verwendete KI-Modell als „Gehirn“ benutzt.
Das Coolste daran ist aber, dass man diese Datei wirklich direkt ausführen kann, man muss nichts installieren und die Datei funktioniert auf vielen, verschiedenen Geräten automatisch. Egal, ob das ein Mac mit einem starken, neuen M-Chip ist, ein Windows-Laptop oder sogar ein Raspberry Pi – Llamafile will KI in die Hände von so vielen Personen wie möglich bringen.
Wo finde ich Llamafile?
Das Llamafile Projekt hat ein eigenes GitHub Repo. Dort findet man immer aktuelle Informationen über das Projekt selbst, sowie die aktuellste Version der Software.
Wie kann ich mit Llamafile KI-Modelle lokal verwenden?
Es gibt mehrere Möglichkeiten, wie man die KI-Modelle mit Llamafile verwenden kann. Hier stellen wir Dir alle verschiedenen Wege vor.
Möglichkeit 1: Fertige Llamafile-Dateien verwenden
Direkt auf der GitHub-Seite von Llamafile findet man unter dem Abschnitt Quickstart die einfachste Möglichkeit:
Man kann hier einfach eine fertige Datei, ein Llamafile, herunterladen und direkt ausführen und den Chatbot benutzen. Im Abschnitt Quickstart ist das Llava-Modell dafür vorgestellt, direkt darunter finden wir aber unter Other example llamafiles noch weitere Modelle, zum Beispiel Lama, Mistral oder Phi als direkten Download.
Nachdem die Datei heruntergeladen wurde, muss man kurz das Terminal benutzen und einen, bzw. zwei kurze Befehle eingeben.
Llamafiles unter Mac und Linux ausführen
Wenn man Mac oder Linux verwendet, dann muss als Erstes folgender Befehl im Terminal ausgeführt werden. „llava-v1.5-7b-q4.llamafile“ muss dabei mit dem Namen der Datei ersetzt werden.
chmod +x llava-v1.5-7b-q4.llamafileDieser Befehl fügt der Datei die Berechtigung zum Ausführen hinzu, wird dieser Schritt weggelassen, kann die Datei nicht ausgeführt werden. Und dann können wir direkt genau das tun, mit folgendem Befehl im Terminal:
./llava-v1.5-7b-q4.llamafileLlamafiles unter Windows ausführen
Unter Windows können wir im Prinzip direkt die Llamafile-Datei ausführen und müssen nicht zuerst Berechtigungen im Terminal erteilen. Allerdings müssen wir die Datei umbenennen und die Endung .exe anhängen, damit das Ausführen funktioniert.
Sobald wir die Datei umbenannt haben können wir auch hier einfach den folgenden Befehl im Terminal eingeben:
./llava-v1.5-7b-q4.llamafile.exeBei Windows kann es je nach Version auch sein, dass wir den Slash am Beginn umdrehen müssen. Wenn dieser Befehl so nicht funktioniert, dann müssen wir es so schreiben:
.\llava-v1.5-7b-q4.llamafile.exeLlamafile Chatbot im Browser verwenden
Man sieht dann, egal ob Mac, Linux, oder Windows zunächst einmal einiges an Output in der Konsole, aber nach kurzer Zeit sollte sich im Standardbrowser des Computers ein neues, lokales Tab mit der Adresse „http://127.0.0.1:8080“ öffnen. Das sieht dann aktuell so aus:

Im oberen Bereich können wir einige Einstellungen vornehmen, wie sich das KI-Modell verhalten soll, darauf gehen wir in diesem Tutorial aber nicht genau ein. Unten haben wir ein Eingabefeld für unseren Prompt und können dort direkt unsere Nachricht eingeben und abschicken.
Einige Modelle, wie das Demo-Modell Llava, das hier verwendet wird, haben zudem Vision-Fähigkeiten, das bedeutet wir können hier sogar Bilder hochladen und diese analysieren lassen.
Wo findet man mehr Llamafiles?
Neben dem Github Repo von Llamafile selbst, gibt es mittlerweile auf Huggingface einen extra Filter für Modelle, die man direkt als Llamafile herunterladen und sofort ausführen kann. Mit diesem Link kommst Du direkt zur Liste mit allen verfügbaren Modellen.
Beim entsprechenden Modell kann man dann „Files and Versions“ auswählen und sieht dort in der Liste alle verfügbaren Downloads.
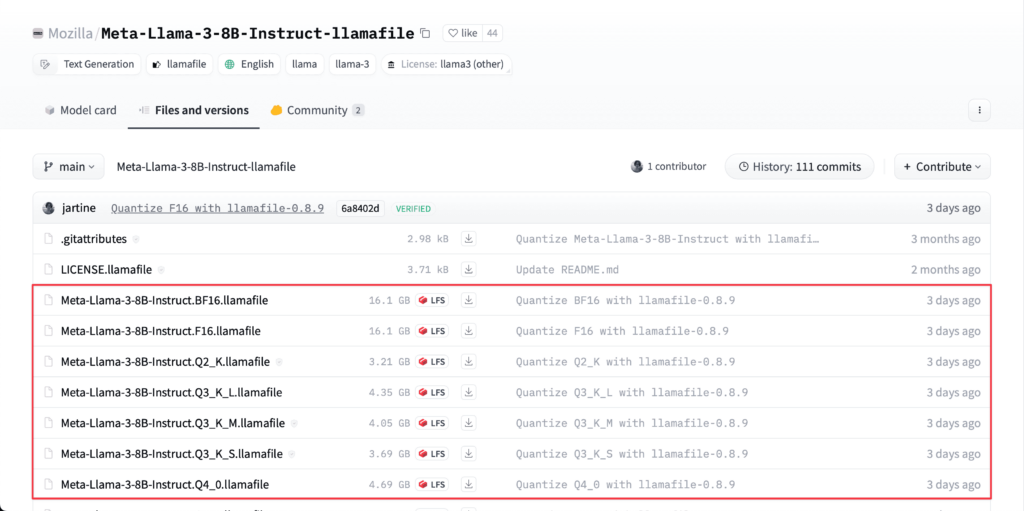
Sobald die Datei heruntergeladen ist, kann man sie direkt wie gerade eben beschrieben mit dem entsprechenden Terminal-Befehl ausführen und chatten. Zu beachten ist lediglich für Mac und Linus das Erteilen der Berechtigung für das Ausführen und für Windows das Umbenennen mit der Dateiendung .exe
Möglichkeit 2: Eigene Llamafiles aus öffentlich verfügbaren KI-Modellen erstellen
Diese Möglichkeit ist unglaublich cool, denn mittlerweile ist es dank der vielen Arbeit der Freiwilligen am Open Source Projekt Llamafile extrem einfach aus GGUF-Dateien, die die Gewichtungen der Modelle enthalten mit nur einem Terminal-Befehl ein Llamafile zu erstellen und dieses dann wie schon gelernt einfach auszuführen.
Damit das funktioniert müssen wir aber zunächst einmal die neueste Version von Llamafile herunterladen und installieren. Im Github Repo findet man hier unter Releases ganz oben die neuste Version. Am besten ist es, den eigentlichen Code herunterzuladen also die Source Code Variante und Llamafile dann selbst zu installieren, damit die Kommandos überall im Terminal funktionieren.

Für Mac und Linux geht das super einfach. Wir laden die Dateien herunterladen, und wechseln dann im Terminal in den Ordner. Dieser sollte eine Datei mit dem Namen „Makefile“ enthalten. Wenn wir uns in diesem Ordner befinden, führen wir folgenden Befehl im Terminal aus:
sudo gmake install PREFIX=/usr/localUnter Windows ist das leider mit deutlich mehr Aufwand verbunden, daher kann man hier auch einfach die fertige Datei herunterladen. Wichtig dabei ist aber, dass das nur funktioniert, wenn man erstens wieder die Dateiendung .exe durch Umbenennen der Datei hinzufügt und dann in das richtige Verzeichnis wechselt, bevor man die Datei verwendet. Nehmen wir an, meine Datei liegt im Downloads-Ordner, dann müssten wir zunächst einmal folgenden Befehl verwenden:
cd ""C:\Users\[username]\Downloads"Man kann nach dem cd Kommando einfach mit Drag and Drop den Ordner, in dem die exe-Datei liegt in das Terminal ziehen, dann wird der Pfad automatisch ergänzt.
Um jetzt ein eigenes Llamafile zu erstellen, benötigen wir eine GGUF-Datei, die wir für die meisten Open Source Modelle eigentlich ganz leicht finden, indem wir entweder einfach „MODELLNAME gguf“ in der Google Suche eingeben oder aber direkt bei Huggingface die Modelle nach GGUF filtern und dort haben wir eine riesige Auswahl zur Verfügung.
Wenn dann Llamafile und ein passendes Modell vorhanden sind, kann ich mit der Umwandlung starten. Je nachdem, ob ich Llamafile selbst installiert habe, oder eine fertige Version heruntergeladen sehen die Befehle etwas anders aus. Beginnen wir wieder mit selbst installiert unter Mac/Linux:
llamafile-convert [Pfad oder Name der GGUF Datei]Unter Windows mit der fertigen Llamafile-Datei würde der Befehl so aussehen:
.\llamafile-0.8.9.exe -convert [Pfad oder Name der GGUF Datei]In beiden Fällen habe ich dann aber erfolgreich die GGUF-Datei in ein ausführbares Llamafile konvertiert und kann dieser wieder genau so wie bei Möglichkeit 1 beschrieben ausführen und chatten.
Möglichkeit 3: Llamafile mit externen GGUF-Dateien verwenden
Die dritte Möglichkeit bietet sich besonders für Windows-User an, denn mit diesem kleinen Trick können wir das Limit von ca. 4GB für die ausführbaren Dateien unter Windows umgehen. Wenn ein Llamafile zu groß wird, dann kann man das mit Windows gar nicht mehr benutzen, aber es funktioniert eben auch, wenn wir zusätzlich zur ausführbaren Datei eine externe Datei, sozusagen für das KI-Modell, verwenden.
Im Prinzip funktioniert alles genau gleich, wie bei Möglichkeit 2, als wir eigene Llamafiles erstellt haben. Wir benötigen also die leere Version von Llamafile und eine Modell-Datei im Format GGUF.
Jetzt geben wir folgenden Befehl im Terminal ein:
.\llamafile-0.8.9.exe -m [Pfad oder Name der GGUF Datei]Das funktioniert natürlich auch für Mac und Linux, wenn man das möchte, hier sieht der Befehl so aus:
./llamafile -m [Pfad oder Name der GGUF Datei]Und auch hier bekommen wir das selbe Ergebnis: Unseren gewohnten Chatbot im lokalen Browsertab.
Was ist die beste Hardware für Llamafile?
Die coolste Eigenschaft für die Verwendung von KI-Modellen mit Llamafile ist, dass wir eigentlich keine spezielle Hardware brauchen, wir sind nicht auf ein bestimmtes Betriebssystem eingeschränkt und seit den neuen Versionen kann man Llamafile sogar auf Android Smartphones oder einem Raspberry Pi verwenden.
Aber natürlich hängt die Leistung immer auch ein bisschen von der Hardware ab und natürlich benötigt man für die Verwendung von besseren KI-Modellen wie Gemma 2 27B oder Mixtral 8x22B mehr als nur ein Einstiegslaptop.
Aber durch die vielen Optimierungen des Teams von Mozilla ist es nicht entscheidend, ob man eine teure Grafikkarte hat, man kann auch schon mit einer guten CPU und ordentlich Arbeitsspeicher viel erreichen.
Natürlich kann man sagen, mehr ist immer besser. In der Diskussion auf der GitHub-Seite finden sich allerdings einige Benchmarks von Setups, die getestet wurden und da haben wir eines mal herausgepickt, das für viele durchaus realistisch sein kann.
Hier wurde ein AMD Ryzen 9 5950X 16-Core Prozessor mit 128 GB DDR4-Ram verwendet. Dieser Prozessor ist für 350-400 € zu haben und auch den Arbeitsspeicher kann man durchaus bezahlen, wenn man sich so eine Workstation bauen will.
Mit dieser Konfiguration wurden für das Mixtral 8x22B Modell fast 20 Tokens pro Sekunde erzielt. Jetzt kann man argumentieren, dass das nicht sonderlich schnell ist, aber wie hat es Justine Tunney in der Demo so schön gesagt: Performance ist schön, aber eigentlich ist das was wir wollen Intelligenz.
Und die bekommen wir bei Modellen in dieser Größenordnung auf jeden Fall. Da warte ich lieber auch mal 1-2 Minuten länger auf eine Antwort, wenn diese dafür eben wirklich gut ist.
Und zum Vergleich: Die Alternative für dieses Modell mit guter Leistung wäre ein Setup mit zwei Nvidia RTX 4090 Grafikkarten, die jeweils ca. 1.700-1.800 € kosten würden. Da kommt man dann mit Llamafile doch deutlich besser weg.
Mögliche Probleme bei der Arbeit mit dem Terminal
Die Arbeit mit dem Terminal und diesen Konsolenbefehlen kann, vor allem für Neulinge, immer wieder Probleme verursachen oder eben einfach nicht auf Anhieb funktionieren. In diesem Abschnitt haben wir einige mögliche Stolpersteine zusammengefasst und was man dagegen tun kann.
Problem 1: Alte Xcode-Version von make funktioniert nicht
Dieses Problem betrifft nur Mac User. Xcode verwendet standardmäßig noch eine sehr alte Version des make-Befehls, die nicht mit Llamafile funktioniert. Um das Problem zu beheben müssen wir die neue Version installieren und verwenden dafür folgenden Befehl:
brew install makeProblem 2: Brew ist nicht installiert
Dieses Problem können wir haben, wenn wir versuchen unser erstes Problem zu lösen und gar nicht in der Lage sind, die neue Version von make zu installieren. Auch dafür gibt es aber Abhilfe und zwar mit diesem Befehl:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"Problem 3: Llamafile ist zu groß und kann auf Windows nicht ausgeführt werden
Leider können ausführbare Dateien auf Windows nicht wirklich größer sein als 4 GB. In diesem Fall bleibt nichts anderes übrig als die hier im Artikel vorgestellte Möglichkeit 3 zu verwenden und ein „leeres“ Llamafile mit einer externen Modell-Datei zu kombinieren. Das ist aber an sich nicht schlimm und funktioniert genauso gut – man braucht nur eben zwei Dateien.

