ChatGPT, Claude, Gemini, Llama, Mistral – es gibt ja wirklich mittlerweile Chatbots wie Sand am Meer und jeder behauptet der Beste zu sein. Für uns als normale User ist es deshalb oft schwer, den Bot zu finden, der für uns wirklich am besten geeignet ist.
Natürlich kann man sich Benchmarks anschauen, da findet man dann jede Menge Zahlen, Namen wie HellaSwag oder MMLU und welche Punktzahl welches Modell dort erreicht hat.

Das Problem: Mir sagt das erst einmal gar nichts darüber, wie gut ein Chatbot mit diesem Modell auf meine vielleicht sehr spezifischen Fragen antwortet.
Die Lösung: Auf der Website chat.lmsys.org können wir nicht nur kostenlos und sogar ohne Account ganz schnell und einfach fast alle guten Chatbots nutzen können, sondern auch diese direkt vergleichen, sowohl gezielt als auch anonymisiert, um zu sehen, von welcher KI wir persönlich am Meisten überzeugt sind.
Aber nicht nur wir selbst können vergleichen und entscheiden: Alle Stimmen, die hier gesammelt werden ergeben am Ende eine Rangliste, das sogenannte Leaderboard, mit den besten Chatbots laut Einschätzung von echten Menschen und eben nicht wieviel Prozent eines vorgegebenen Prozesses ein Modell irgendwann mal erreicht hat.
Auf der Website gibt es vier verschiedene Möglichkeiten Chatbots zu testen:
- Arena (Battle)
- Arena (side-by-side)
- Direct Chat
- Vision Direct Chat

Arena (Battle) – Der anonyme Chatbot Vergleich
Im ersten Modus werden anonym zwei zufällig ausgewählte Chatbots verglichen. In einem einfachen Chat-Interface kann ein Prompt eingegeben werden und dann erzeugen beide KIs eine Antwort.

Man kann dann entweder die Unterhaltung weiterführen und die Bots noch weiter prüfen, oder wählt direkt ein Ergebnis aus. Dabei gibt es vier Optionen: Modell A war besser, Modell B war besser, Unentschieden oder Unentschieden, aber beide Modelle waren schlecht.
Wenn während der Unterhaltung die Identität eines Bots „auffliegt“, beispielsweise durch eine Frage nach dem verwendeten Modell, wird die Stimme hier nicht gezählt.
Arena (side-by-side) – Gezielt zwei Chatbots vergleichen
Die zweite Option bietet im Prinzip genau das gleiche Vorgehen an. Der Unterschied ist: Hier werden nicht zwei Chatbots zufällig und anonym ausgewählt, sondern wir können selbst bestimmen, welche beiden KIs wir gegeneinander ins Rennen schicken wollen.

Damit können wir ganz gezielt vergleichen, wie sich bestimmte KI-Modelle gegeneinander behaupten können, wenn wir vielleicht schon einen oder mehrere Favoriten haben.
Direct Chat – Unterhaltung mit einem individuellen Chatbot
In diesem Modus können wir ebenfalls eines der Modelle aus der langen Liste von verfügbaren Bots auswählen und dann einfach eine Unterhaltung mit genau diesem Modell führen. Auch das ist hier ohne Account und komplett kostenlos möglich und bietet damit eine super Möglichkeit auch Modelle wie beispielsweise Claude 3 Opus in Deutschland gratis zu testen.
Einschränkungen
Vor allem bei großen Modellen wie GPT-4 oder eben auch Claude 3 gibt es immer mal wieder ein Limit, das erreicht wird und man kann nicht sehr lange am Stück damit arbeiten und hunderte Nachrichten pro Stunde verschicken.
Außerdem fehlen natürlich bei entsprechenden Modellen multimodale Fähigkeiten wie Bilderkennung, Erstellung oder Daten-Analyse.
Vision Direct Chat – Begrenzte Auswahl an Bilderkennungs-Chatbots
Der Vollständigkeit halber erwähnen wir auch den Bereich Vision Chat. Hier haben wir einige wenige Chatbots zur Auswahl mit denen wir mit Bilderkennung arbeiten können. Die Auswahl ist aber sehr überschaubar (Stand 28.03.2024 gibt es drei KI-Modelle) und der Hauptfokus der Chatbot Arena liegt deutlich auf dem Vergleich von Text-Bots und der daraus resultierenden Rangliste.
Das Chatbot Arena Leaderboard – Das sind die besten KI-Chatbots
Genauso interessant wie das Ausprobieren der verschiedenen Chatbots ist natürlich die von allen Usern erstellte Rangliste mit den besten KI-Modellen und Chatbots, die in der Chatbot Arena angezeigt wird. Dabei gibt es 7 Spalten mit Informationen:
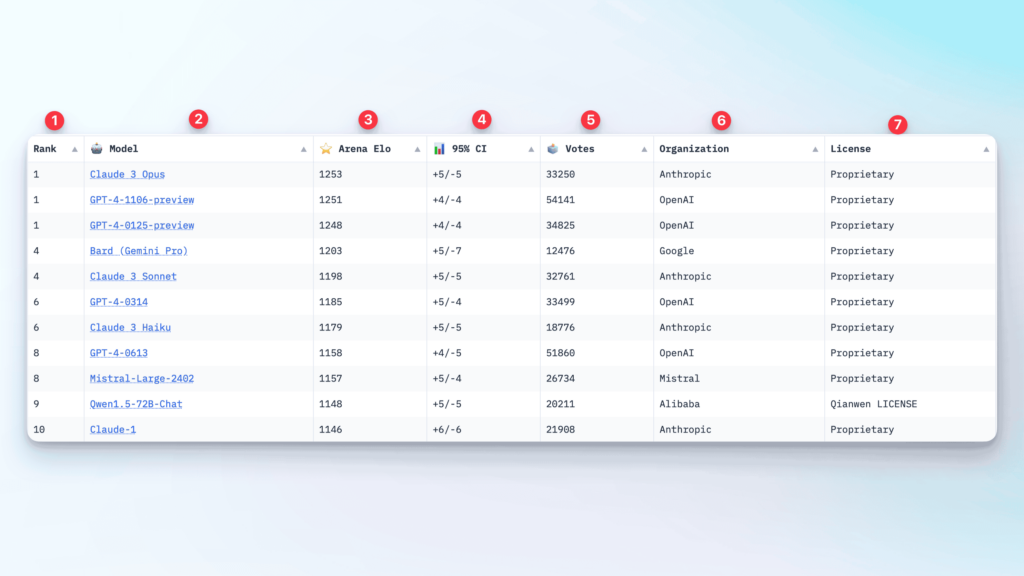
1. Die Platzierung
Dieser Punkt ist vermutlich relativ selbsterklärend, ganz vorne wird angezeigt, welchen Platz dieses Modell im Ranking belegt. Dabei gibt es sehr oft geteilte Plätze, das hängt mit einem weiteren Faktor zusammen, den wir gleich beleuchten.
2. Das Modell
Auch das ist leicht erklärt, in der zweiten Spalte stehen die Modellnamen. Vielleicht als kurzer Hinweis hier, da GPT-4 mehrfach auftaucht. Diese vier Zahlen, die hinter dem Modell stehen, sind amerikanisch formatiere Datumswerte. Bedeutet das Modell GPT-4-1106 ist die Version, die am 06. November veröffentlicht wurde, währen das Modell GPT-4-0125 die momentan aktuellste Version vom 25. Januar ist.
3. Arena Elo – die Punktzahl
In der dritten Spalte steht die Punktzahl, die das Modell erreich hat. Der Wert heißt dabei Arena Elo und wird von der University of California Berkeley, die hinter dem Projekt steht, relativ komplex berechnet. Die genaue Formel und mehr Informationen kann man hier finden.
4. 95% CI – Das Confidence Interval
Hier stehen auf den ersten Blick wahrscheinlich etwas verwirrende Werte, aber die sind der Grund dafür, dass sich viele Modelle Plätze in der Rangliste teilen. Kurz und einfach gesagt: Die Berechnungen ergeben mit 95 prozentiger Wahrscheinlichkeit, dass die Punktzahl des Modells bei der in Spalte drei angegebenen plus/minus den hier stehenden Werten liegt.
Auf unserem Screenshot sehen wir, dass die ersten drei Modelle mit 1248, 1251 und 1253 Punkten nur 5 Punkte auseinanderliegen, mit Abweichungsmöglichkeiten von plus/minus vier bzw. fünf und dadurch kann sich die Reihenfolge hier ändern.
5. Votes – So viele Stimmen hat das Modell bekommen
Ab jetzt wird es wieder einfacher. An der Stimmenzahl sehen wir, wie oft ein Modell als Gewinner ausgewählt wurde. Hier erkennt man auch deutlich beispielsweise an den GPT-4 Varianten, welche schon länger zur Auswahl stehen und dadurch eben auch deutlich mehr Stimmen erhalten konnten.
6. Organization – Von wem stammt das Modell
In dieser Spalte steht das Unternehmen, das dieses Modell entwickelt hat. Bei den großen, bekannten Modellen ist das ja eigentlich klar, aber es gibt eben auch viele unbekanntere Modelle in der Liste. Hier kann man ein bisschen recherchieren, woher diese jeweils kommen.
7. License – Wie wird das Modell entwickelt
Die Lizenz zeigt zunächst einmal klar den Unterschied zwischen Closed Source und Open Source Projekten. Alle Lizenzen, die Proprietary sind, signalisieren klar, dass es sich hierbei um Closed Source Modelle von Unternehmen handelt, die keine Informationen über Modelle, Trainingsdaten oder Ähnliches an die Öffentlichkeit geben.
Bei anderen Modellen stehen verschiedene Lizenzen, auf die wir an dieser Stelle aber nicht im Detail eingehen. Diese Modelle sind teilweise mehr oder weniger Open Source und können kopiert oder analysiert werden.
Mehr Informationen zur Methodik und Daten
Die Chatbot Arena ist eine richtig coole Website und auch für absolute KI- und Chatbot-Neulinge perfekt geeignet. Ohne Account und kostenlos kann man hier einfach ein bisschen herumspielen, verschiedene Modelle ausprobieren und vergleichen.
Aber hinter dem Projekt steht auch eine ziemlich tiefsehende Analyse und Bewertung der Modelle und wer sich da richtig in die Daten stürzen will, kann das auf jeden Fall tun. Bei Huggingface sind weitere Diagramme und Daten zum Leaderboard verfügbar.
Außerdem findet man von der UC Berkeley selbst bei Colab noch genaue Beschreibungen zur Methodik und Formeln. Das ist aber sicherlich nur für die wirklich Datenbegeisterten unter euch relevant.
